✨Generating Bloxorz Game Levels with GPT-2
🎮Game 🧩Puzzle 🤖Algorithm 🎲PCG 💻Game Dev

Want to try the game first? You can play the web demo version here. Don’t forget to add it to your Steam wishlist!
This blog post explores how to generate Bloxorz game maps using GPT-2, a topic that has not been addressed with LLM + PCG techniques before.
Why LLM+PCG
In modern video game development, producing game design content is a representative bottleneck that requires high costs and time investment. The market is changing rapidly, and notably, more games are being released on the Steam platform every year. 1 Among all games released on Steam in 2024, 98.9% were indie games 2, showing an overwhelming proportion of small-scale developers. The smaller the development company, the more limited the manpower and resources, which increases the burden of game design content production. Recently, in the fields of game art and marketing assets, various content production has become possible with tools like Stable Diffusion, Midjourney, and Veo3, but specialized content production tools and techniques targeting game design are still lacking.
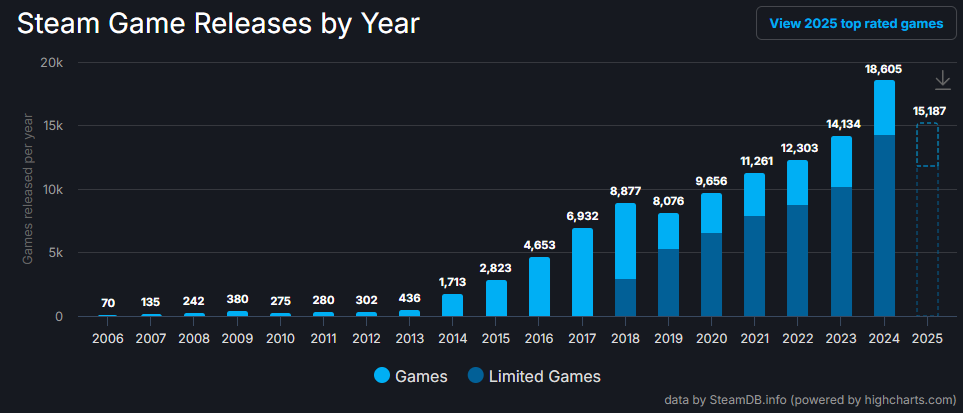
Statistics on the number of games released on Steam each year
The infinite possibilities when LLM is applied to other fields, combined with the fact that no remarkable achievements have been made in this area yet, are attracting game developers and researchers to game design content production. Recent major research includes Sokoban level generation through direct level data learning 3, VGDL (Videogame Description Language)-based simultaneous game and rule/level generation 4, and automatic PuzzleScript game generation and testing 5.

Prompt structure for VGDL (Videogame Description Language)-based simultaneous generation of games and rules/levels. It learns game rules and level structures together.4
Bloxorz
Bloxorz is a classic puzzle game famous for its simple rules and high difficulty, which gained great popularity during the Adobe Flash era in the mid-2000s.

Players must roll a 1x1x2 rectangular block with arrow keys to fit it precisely into a designated hole. The floor has various gimmicks, including bridges that can be created or removed, orange blocks that collapse unless weight is distributed, and switches that temporarily split the block into two pieces.
The controls are very easy and responsive, but the game requires players to think about many elements, such as moving a 3D block to progress and facing game over with a single mistake, which creates an engaging gaming experience.
Traditional Puzzle Design Method: Backward Reasoning
One traditional puzzle design method is backward reasoning. Starting from the solution state, you take actions in reverse to move to the initial state.
Let’s apply this method to Bloxorz puzzle maps. While the game is 3D, the map itself is 2D, consisting of tiles without different heights. There are empty spaces and spaces where blocks can be positioned. If we set empty spaces as _, spaces where blocks can be positioned as ., and the goal point as g, we can represent an example map on a 6x6 grid like this:
...___
_...._
_...._
_.....
_...g.
_.....

How should we determine the starting point with the backward reasoning technique? First, we must start from the solution state, so we start at point g. Let’s arbitrarily mark the block as 1.
...___
_...._
_...._
_.....
_...1.
_.....

What about the next state? There are two cases where the block can move to reach the correct position. Moving right or down would cause the block to fall below the game space and end the game, so these are not appropriate actions.

Continue taking actions this way, and set the game starting position as a state sufficiently far from the goal. Any repetitive movements in between should be removed. For example, starting from the top-left starting point as shown below, the problem can be solved in just 6 turns.

This is called search-based generation technique. What’s the problem? First, code processing becomes complex when gimmicks are intertwined. In the case of the bridge gimmick below, it must start in an activated state and then be deactivated. If there are about two more such gimmicks, each case must be considered.

Additionally, as the search space grows, the number of nodes to search increases exponentially. While effective search techniques can be used to prune as much as possible, otherwise problems such as infinite loops may occur. If you present “a problem that requires at least 20 moves on a 12x12 map,” the backward reasoning technique may or may not be effective. And having more tools in the toolbox is always better than having fewer. The tool newly attracting attention from PCG researchers is LLM.
GPT-2
GPT-2 is the second version of OpenAI’s large-scale artificial intelligence language model released in 2019. The parameters, which are used as a unit almost equivalent to LLM performance, range from 117M to 1.5B in various sizes. The successor model GPT-3 had a significantly increased parameter size of 175B, and as of 2025, LLMs have parameters ranging from tens of billions to hundreds of billions. In short, GPT-2 has lower performance than current LLMs.
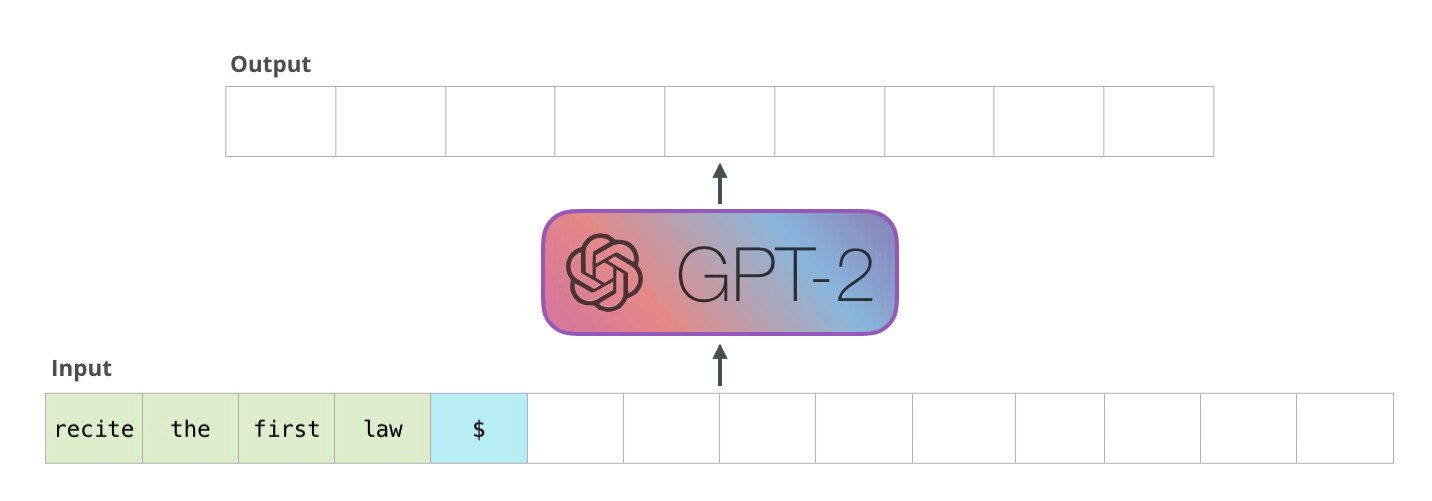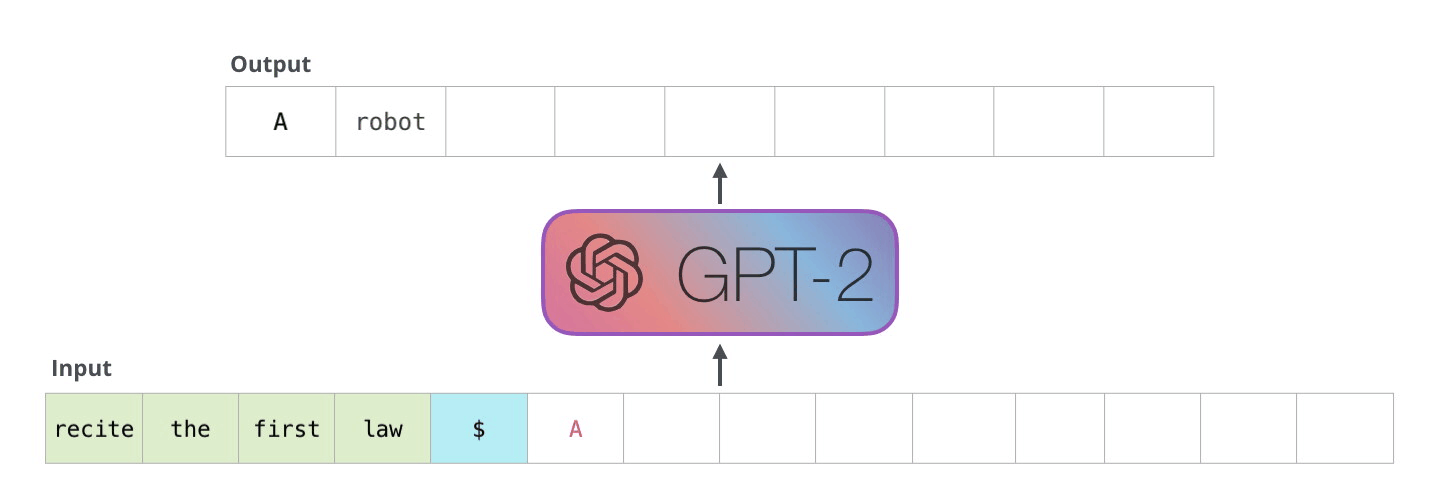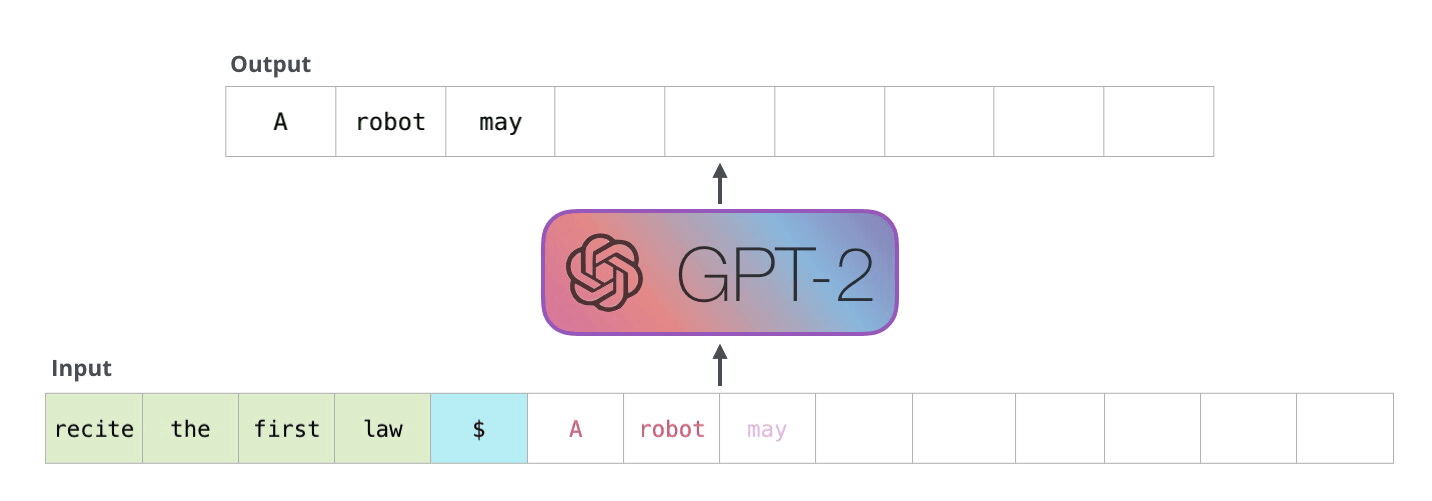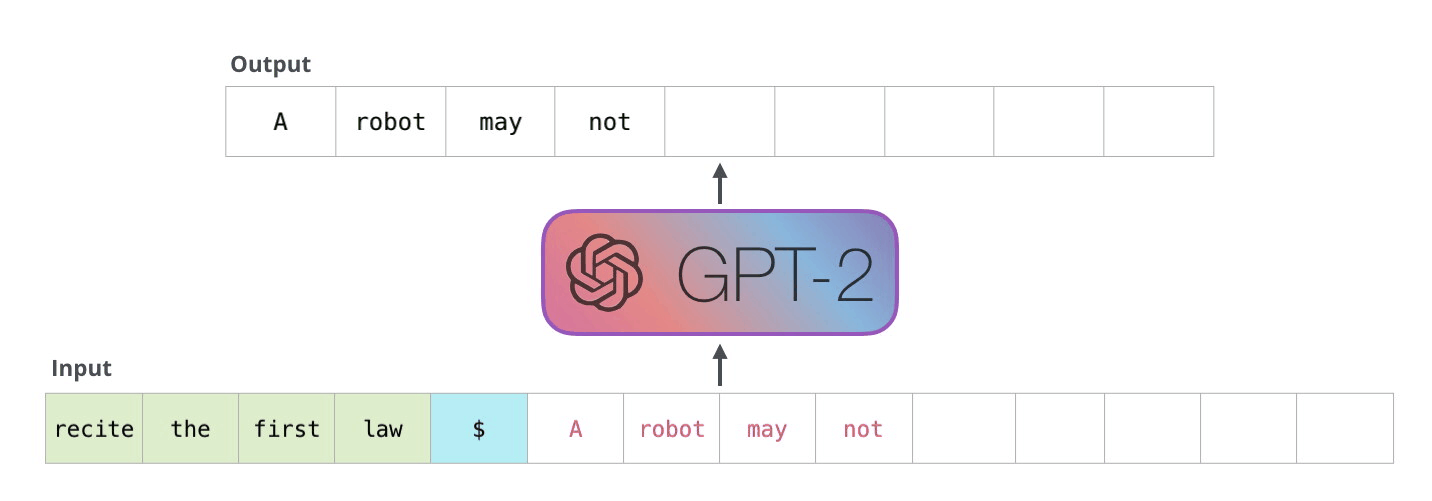
GPT-2, auto-regressive model. Image Source Link
GPT-2 is auto-regressive. This characteristic means that generated tokens are added to the input sequence at the next step, becoming new input. Game levels have sequential dependencies—when a block is placed, there’s a high probability that related blocks will be placed next to it—which makes auto-regressive generation a useful feature for game level generation. For example, in Super Mario, if you place a block at a certain position, the adjacent space must be within jumpable distance and there must be a platform to land on.

A research example that uses GPT-2 to create practical game levels is “Level generation through large language models”3. This 2023 study from New York University generates Sokoban levels. Sokoban is a puzzle game released in 1982 by Japanese software company Thinking Rabbit, where players must push boxes in a warehouse to designated locations. Countless games have been influenced by it, including Baba is You and Monster’s Expedition, making Sokoban recognized as its own genre. Due to its high difficulty, it functions as one of the benchmarks for level generation algorithms.
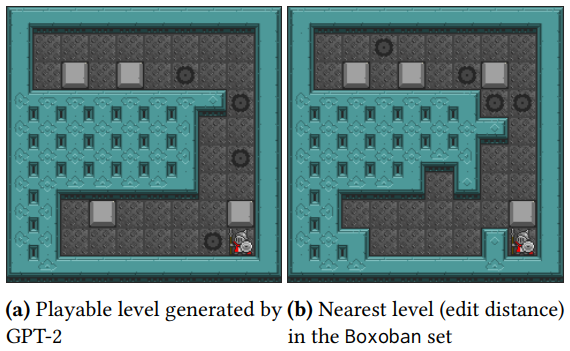
The above results demonstrate that the LLM didn’t simply memorize the original data by generating levels with GPT-2 and then comparing them with the levels in the original Boxoban dataset that have the closest edit distance.
While the research also covers GPT-3, GPT-2 can generate maps that are suitable for use, and crucially, it is appropriate for training on a local computer with around 8GB of GPU RAM, so we will continue to use GPT-2 here.
Generating Mindcraft Game Levels Using GPT-2
This blog covers how to generate game levels by adapting the above research and code base to change the game domain to Mindcraft.
The code covered in this blog can be found here. Testing was completed on Windows 11, and it has not been tested on other operating systems.
Mindcraft is a block-rotating puzzle game heavily influenced by Bloxorz, featuring about 10 gimmicks not present in the original, 198 completely new maps, and 7 beautiful world themes.
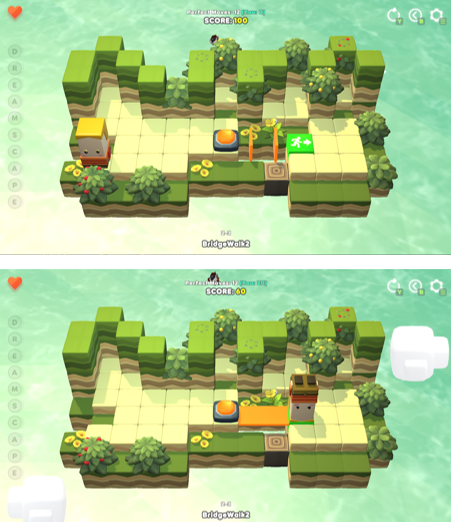
Initial state and near-completion state of a map with the bridge gimmick
Original Data
Demo Video 1: Mindcraft Puzzle Visualizer

Here, we verify whether new levels can be generated for cases with no gimmicks in the map, only the glass gimmick, only the bridge gimmick, and only the switch gimmick. The original maps are located under the data/bloxorz folder and are as follows:
- puzzle_no_gimmick_all.json
- puzzle_bridge_all.json
- puzzle_glass_all.json
- puzzle_switch_all.json
To view the original maps, you can run visualizer.html located in the same folder. To run it on a web server, follow these steps:
-
Download the Windows Installer from the Simple Webserver site.
-
Register the path where visualizer.html is located as a new entry in the web server.
-
Enter the web server address in the address bar or click the generated local web server’s Web Server URL to access the local web server.
-
Click visualizer.html to launch the visualization tool.
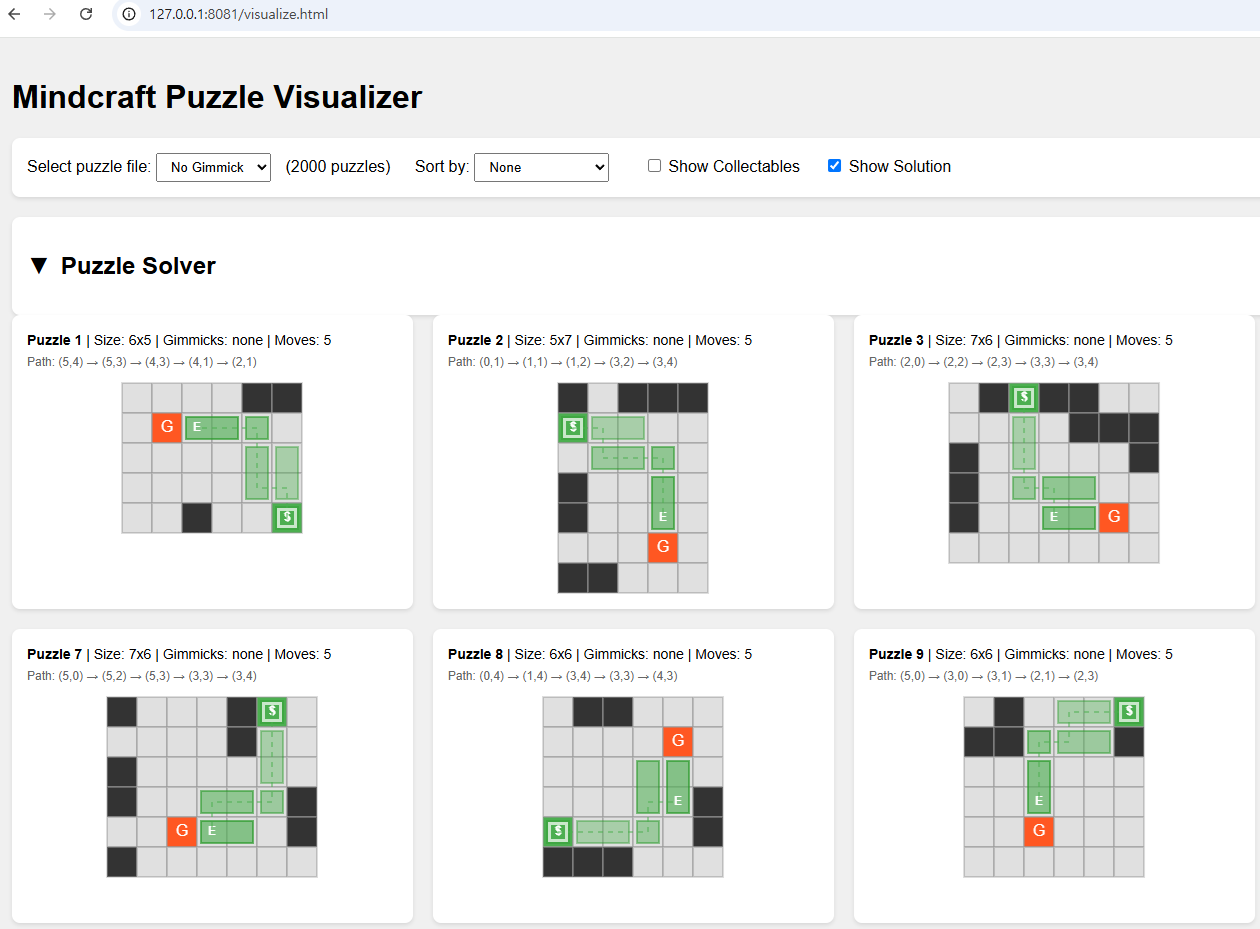
We have prepared over 2,000 maps for each type, and you can sort the maps by solution length (corresponding to difficulty) and switch count (which only applies to the switch gimmick).
To summarize the symbols used in the maps:
_: Empty space. If any part of the block is positioned on this, it falls down and the game is over.
.: Ground. The block can be positioned here.
1: Starting position of the player block.
g: Goal point. The game is cleared when the player block reaches this in a vertical (standing upright) state.
h: Bridge activation switch. Can only be pressed once.
H: The actual bridge that is activated when the bridge activation switch is pressed. Before activation, it functions the same as empty space—if positioned on it, the block falls down and the game is over.
*: Glass gimmick. Works similarly to ground, but if the player block reaches it in a vertical state, the weight is not distributed and it falls down, resulting in game over.
a, b, c, d, e: Switches. Each corresponds to a wall of the same uppercase letter. Can only be pressed once.
A, B, C, D, E: Walls that move when switches are pressed. When a switch is pressed, the wall lowers and functions the same as ground.
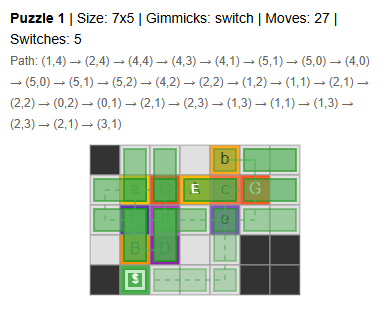
Example of a map with five switches. It’s complex, with a minimum move count of around 27.
Fine-tuning GPT-2 Using LoRA
Demo Video 2: Generating Regular Maps Without Gimmicks with GPT-2
Now, let’s train GPT-2 using the original data. Simply training GPT-2 would take a significant amount of time even on a 16GB RAM GPU like the RTX 4080, so we proceed with PEFT (Parameter-Efficient Fine-Tuning), specifically using the LoRA (Low-Rank Adaptation) method. Compared to training all parameters, multiple studies have shown that LoRA enables training even in limited memory environments, with faster training time and virtually no degradation in performance.
The training structure is as follows. The overall structure uses a supervised learning approach that trains on input and output text pairs, teaching the model to produce the corresponding output when given an input.
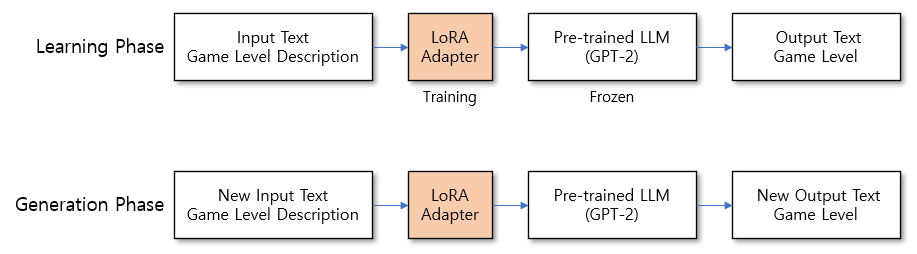
Learning phase and generation phase
In the learning phase, the pre-trained LLM’s parameters are frozen while only the LoRA adapter’s parameters are updated during training. At this time, the input and output texts are processed from pre-prepared map data.
In the generation phase, we randomly generate new input text that was not seen during the learning phase and verify whether appropriate new output text is produced. The criteria for “appropriate” here are Novel, Valid, and Accurate, which will be discussed later.
The input text follows this format:
STARTGrid size: 7x6
Block types: 3
Glass tiles: 0
Switches: 0
Bridges: 0
Collectables: 0
Move length: 5
Difficulty: easy
The first START indicates the beginning of the input. The subsequent inputs have the following meanings:
| Item | Meaning | Notes |
|---|---|---|
| Grid size | Width x height of the level | |
| Block types | Number of different block states used in the solution | |
| Glass tiles | Number of glass tile gimmicks | |
| Switches | Number of switch gimmicks | |
| Bridges | Number of bridge gimmicks | |
| Collectables | Number of collectible items | |
| Move length | Number of moves required for solution | |
| Difficulty | easy/medium/hard | easy if move length < 10 medium if < 20 hard if ≥ 20 |
And we train it to output text in the following format:
._1__..
....___
_....._
_......
_....g.
.......END
END indicates the end of the output.
The figure below is a visualization of the above map data.
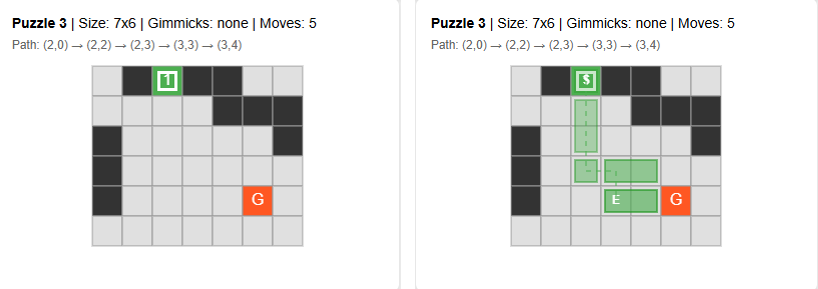
A notable point in this process is that solution information is not included in the input. This was also the case when creating Sokoban maps in the original paper—even without including solution information, the LLM consistently produces solvable maps with solutions as it continues to learn.
For training, it is recommended to run in an anaconda environment with PyTorch and related libraries installed, preferably on a system with at least 8GB RAM GPU.
First, let’s try generating regular maps without gimmicks using GPT-2, an LLM with a smaller parameter count.
python train_simple.py model=gpt2 lora=True exp_name=no_gimmick num_train_steps=10000
Once training starts, it will complete in a few minutes to tens of minutes depending on your GPU. Every 1,000 train steps, you can verify that training is progressing well by checking the output results for sample inputs.
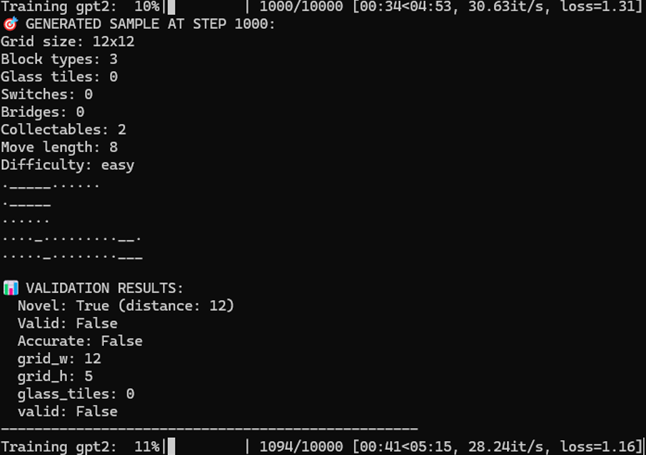
Checking output with sample input during LLM training
Novel, Valid, and Accurate displayed below the sample output have the following meanings:
- Novel: Calculates the Levenshtein distance with all levels in the training data to find the minimum distance, and judges it as Novel if the distance is 10 or more. Levenshtein distance is the distance between two strings. For example, the distance between “aab” and “aaa” is 1.
- Valid: Checks whether the generated level is actually playable. In other words, it checks whether there is a solution, whether it is rectangular in shape, whether there is exactly one start point and one goal point, and whether only valid characters are used.
- Accurate: Checks whether the generated level matches the input prompt. For example, whether the Grid Size is correct, whether the counts of Glass, Switch, Bridge, etc. match.
Below is the input and output when GPT-2 is trained for 10,000 steps.
🎯 GENERATED SAMPLE AT STEP 10000:
Grid size: 10x12
Block types: 3
Glass tiles: 0
Switches: 0
Bridges: 0
Collectables: 2
Move length: 15
Difficulty: medium
...__.._
_..._____
_........
..g.......
......__._
.......__..
...___..
......__..
..__....__
..__..__....
📊 VALIDATION RESULTS:
Novel: True (distance: 21)
Valid: False
Accurate: False
grid_w: 8
grid_h: 10
glass_tiles: 0
valid: False
While it satisfied Novel, it is not rectangular in shape, has no visible start point, and grid_w and grid_h do not match, so both Valid and Accurate are False.
The GPT-2 used in this project is the base model with a parameter size of 124M. This time, let’s train with gpt2-xl (1.5B), which has about 12 times more parameters than the base model. Just change the model part in the GPT-2 training command to gpt2-xl.
python train_simple.py model=gpt2-xl lora=True exp_name=no_gimmick num_train_steps=10000
The gpt2-xl model is about 6.43GB in size, so if you’re running it for the first time, you’ll need some time to download the model.

Downloading the gpt2-xl model
After the model is downloaded, training begins. While the base model failed to generate proper maps, gpt2-xl can generate plausible maps like the one below.
🎯 GENERATED SAMPLE AT STEP 9000:
Grid size: 11x10
Block types: 3
Glass tiles: 0
Switches: 0
Bridges: 0
Collectables: 1
Move length: 16
Difficulty: medium
__....1_
_.......
_.......
..._....
..._....
..___.._
..__..__
......._
......._
.g.__.._
......_.
📊 VALIDATION RESULTS:
Novel: True (distance: 18)
Valid: True
Accurate: False
grid_w: 8
grid_h: 11
glass_tiles: 0
valid: True
This map is novel and has a solution, but there’s an issue that the grid size came out as 8x11 instead of 11x10. Still, this is a map that can be used in the game.
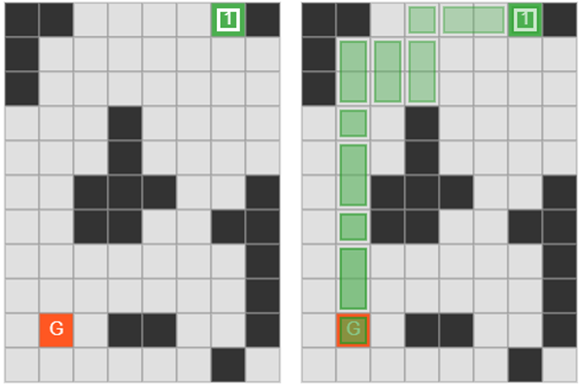
Visualization and solution of a map generated by gpt2-xl

The map generated by gpt2-xl placed in the actual game. Empty spaces inside and outside the game area are filled with decorative elements (deco)
If you change one tile near the goal point in the above map from ground to empty space, it will fail to find a solution.

Changing one tile near the goal point to empty space in the map
Now, by changing the experiment name to glass, we can verify whether the LLM can learn and generate maps with gimmicks as well. Enter the following command to start training.
python train_simple.py model=gpt2-xl lora=True exp_name=glass num_train_steps=10000
One of the maps generated after training produces a solution well as shown below. The Move length is 8, which differs by only 1 from the given input value of 7.
🎯 GENERATED SAMPLE AT STEP 9000:
Grid size: 9x5
Block types: 2
Glass tiles: 20
Switches: 0
Bridges: 0
Collectables: 1
Move length: 7
Difficulty: easy
**.*..._
.*.*g..*
...*.*.*
*..*..*_
_..*..__
**.*...*
**.*.*.1
📊 VALIDATION RESULTS:
Novel: True (distance: 19)
Valid: True
Accurate: False
grid_w: 8
grid_h: 7
glass_tiles: 21
valid: True
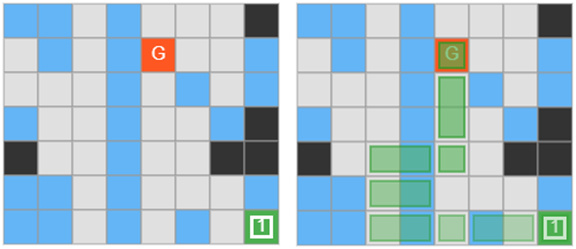
Visualization and solution of a glass map generated by gpt2-xl

The map generated by gpt2-xl placed in the actual game. The glass gimmick is represented with tiles that look fragile
Verifying Map Generation Results
Now, let’s generate multiple actual levels with the trained LLM and evaluate how well the levels meet the Novel, Valid, and Accurate criteria.
Enter the following command to generate and evaluate 100 maps using the GPT-2 base model trained on maps without gimmicks.
python evaluate_simple.py ./logs/no_gimmick_gpt2_lora
And do the same with the gpt2-xl model as well.
python evaluate_simple.py ./logs/no_gimmick_gpt2-xl_lora
The results are as follows. The gpt2-xl model’s results after running the same number of train steps are generally superior to the gpt2 base model, with the proportion of Novel+Valid maps that can be used directly in the game reaching 22%. It can also be confirmed that at the 10,000 train step level, it is difficult to generate maps that satisfy all three criteria: Novel+Valid+Accurate.
| Language Model | Train Steps | Novel | Valid | Accurate | N+V | N+V+A |
|---|---|---|---|---|---|---|
| GPT-2 | 10,000 | 96% | 0% | 2% | 0% | 0% |
| GPT-2 XL | 10,000 | 92% | 25% | 5% | 22% | 0% |
Comparison of map generation results between GPT-2 (124M) and GPT-2 XL (1.5B)
Maps with gimmicks can also be generated and evaluated. Enter the following command to generate and evaluate 100 maps using the gpt2-xl model trained to generate glass gimmicks.
python evaluate_simple.py ./logs/glass_gpt2-xl_lora
| Language Model | Train Steps | Novel | Valid | Accurate | N+V | N+V+A |
|---|---|---|---|---|---|---|
| GPT-2 XL | 10,000 | 100% | 50% | 1% | 50% | 0% |
| GPT-2 XL | 50,000 | 100% | 64% | 6% | 64% | 5% |
| GPT-2 XL | 100,000 | 100% | 61% | 2% | 61% | 2% |
Comparison of map generation results according to GPT-2 XL’s train step variations
When increasing the train steps to 50,000~100,000, you can see that the Valid ratio increases, but the Accurate ratio does not increase significantly. However, since Novel+Valid alone is sufficient for use directly in the game, the model’s ability to generate new maps can be considered somewhat validated.
Conclusion
This blog covered how to automatically generate levels for the Mindcraft game using GPT-2. Through efficient fine-tuning using the LoRA technique, we confirmed that practical map generation is possible even in limited GPU environments.
Experimental results showed that while the GPT-2 base model (124M) struggled to generate valid maps, the GPT-2 XL (1.5B) model was able to generate 22% Novel+Valid maps with just 10,000 training steps. For maps containing the glass gimmick, 64% Novel+Valid maps were generated with 50,000 training steps, demonstrating that complex maps with gimmicks can also be effectively learned.
Particularly noteworthy is that the LLM generates solvable maps even though solution information was not included in the input. This means that the LLM inherently learns the game’s rules and playability during the training process.
Although the Accurate metric was low, maps that can be directly used in the game can be generated with just the Novel+Valid criteria, confirming the potential as a practical level generation tool. It is expected that the Accurate ratio can also be improved in the future by using more train steps and larger models, or by improving prompt engineering.
-
Indie Games Market Reached Unprecedented Success in 2024, 80lv ↩
-
Todd, Graham, et al. “Level generation through large language models.” Proceedings of the 18th International Conference on the Foundations of Digital Games. 2023. ↩ ↩2
-
Hu, Chengpeng, Yunlong Zhao, and Jialin Liu. “Game generation via large language models.” 2024 IEEE Conference on Games (CoG). IEEE, 2024. ↩ ↩2
-
Earle, Sam, et al. “ScriptDoctor: Automatic Generation of PuzzleScript Games via Large Language Models and Tree Search.” arXiv preprint arXiv:2506.06524 (2025). ↩